Назначение и области использования
Автоматизация криминалистических фоноучетов на основе выделения и сравнения биометрических признаков речи
Функциональные возможности
Упорядоченное хранение фонограмм речи
Автоматическое выделение биометрических признаков голоса и речи лиц, подлежащих учету
Автоматический поиск лиц с совпадающими или близкими биометрическим характеристиками голоса и речи
Отличительные особенности
Высокая эффективность работы с реальными сигналами, свободной речью
Возможность установления личности по сигналам низкого качества
Использование двух независимых алгоритмов сравнения: формантного и статистики основного тона (начиная с версии 3.0)
Максимальная автоматизации процесса поиска и сравнения, что позволяет минимизировать требования к уровню подготовки обслуживающего персонала и повышает скорость принятия решения
Возможность хранения в фонотеке, наряду со звуковой, текстовой и графической информации
Возможность задания при проведении поиска значений ошибок первого и второго рода
Возможность создания собственной формы учетных карточек
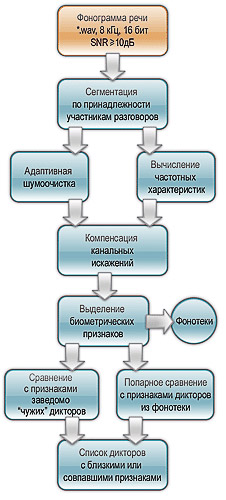
Собственно процедура поиска интересующего лица заключается в автоматическом попарном сравнении «дикторских карточек», в которых закодированы индивидуальные характеристики голоса и речи подлежащих учету лиц. По результатам сравнения выводится список фонограмм, в которых с указанной вероятностью содержится речь интересующего человека.
Основные характеристики «ТРАЛ-M»
Показатели надежности поиска:
(данные показатели получены при тестировании системы на официально зарегистрированной речевой базе)
92% при сравнении пары речевых сигналов длительностью каждого не менее 96 сек
88% при сравнении пары речевых сигналов длительностью 16 сек и 96 сек соответственно
82% при сравнении пары речевых сигналов длительностью 16 сек каждый
не менее 90% при сравнении пары речевых сигналов длительностью 16 сек и 96 сек передаваемых по одному и тому же каналу связи
Время создания одной «дикторской карточки» – 3…4 сек
Время сравнения одной пары «дикторских карточек» (принятия решения о принадлежности голоса и речи конкретному лицу) – не более 0.7 сек (при использовании ПК на базе Pentium III/1ГГц)
Максимальное количество эталонов («дикторских карточек») для проведения автоматического сравнения – 100 000
Минимальный размер «дикторской карточки» — 300 кБ
Состав
Комплекс включает две или более связанных в сеть ПЭВМ с установленным программным обеспечением, работающим в режиме клиент-сервер:
Server — модуль, необходимый для обеспечения хранения и использования «дикторских карточек» в рамках Комплекса и проведения поиска по запросам пользователей
Operator – программное обеспечение для создания, просмотра и редактирования разделов фонотеки, добавления «дикторских карточек» и работы с ними, в т.ч.:
SpeechMarker – программное обеспечение для сегментирования сигнала
FormeBuilder – программное обеспечение для создания фонотек (баз данных), регистрации пользователей Комплекса и управления ими, а также задания структуры фонотеки